TF-IDF統計方法
評估一個字詞對文件集的重要程度。
字詞的重要性隨著它在文件中出現的次數成正比增加,但同時會隨著它在語料庫中出現的頻率成反比下降。
詞頻(term frequency) : 指的是某一個給定的詞語在該檔案中出現的頻率。
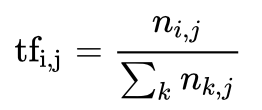
 是該詞在檔案
是該詞在檔案 中的出現次數,而分母則是在檔案中所有字詞的出現次數之和。
中的出現次數,而分母則是在檔案中所有字詞的出現次數之和。
某一特定檔案內的高詞語頻率,以及該詞語在整個檔案集合中的低檔案頻率,可以產生出高權重的tf-idf。因此,tf-idf傾向於過濾掉常見的詞語,保留重要的詞語。
逆向檔案頻率IDF(Inverse Document Frequency) : 是一個詞語普遍重要性的度量。某一特定詞語的idf,可以由總檔案數目除以包含該詞語之檔案的數目,再將得到的商取對數得到。
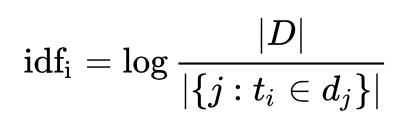
|D|:語料庫中的檔案總數
 包含詞語
包含詞語 的檔案數目(即
的檔案數目(即 的檔案數目)如果詞語不在資料中,就導致分母為零,因此一般情況下使用
的檔案數目)如果詞語不在資料中,就導致分母為零,因此一般情況下使用

某一特定檔案內的高詞語頻率,以及該詞語在整個檔案集合中的低檔案頻率,可以產生出高權重的tf-idf。
評估檢索結果的方法
Precision(查準率) = Relevant Documents Retrieved(抓回來的相關文章數量) / Total Retrieved Documents(抓回文章的總數)
Recall(查全率) = Relevant Documents Retrieved(抓回來的相關文章數量) / Total Relevant Documents(相關文章的總數)
| 相關 | 不相關 | |
|---|---|---|
| 回傳 | tp(true positive) | fp(false positive) |
| 不回傳 | fn(false negative) | tn(true negative) |
Precision = tp / tp+fp
Recall = tp / tp+fn